Racing conditions after an Envoy connection is closed#
Since the following use socket some of the more basic and cold knowledge. For example, the critical state and exception logic of the close socket. If you don’t know much about it, you are advised to read what I wrote first:
《Mark’s DevOps 雜碎》 中 《Critical status and exception logic of Socket Close/Shutdown》 一文。
Envoy and Downstream/Upstream connections are out of sync.#
Most of the cases below are low-probability race conditions, but, under heavy traffic, even the lowest probability can be encountered. It is the programmer’s job to ``Design For Failure’’.
Downstream sends a request to an Envoy connection that is closed.#
Github Issue: 502 on our ALB when traffic rate drops#13388 Fundamentally, the problem is that ALB is reusing connections that Envoy is closing. This is an inherent race condition with HTTP/1.1. You need to configure the
ALB max connection/idle timeoutto be <any envoy timeout.To have no race conditions, the ALB needs to support
max_connection_durationand have that be less than Envoy’s max connection duration. There is no way to fix this with Envoy.
Essentially:
the Envoy closes the socket by calling
close(fd). and closes fd at the same time.If at the time of
close(fd):If at the time of
close(fd): the kernel’s socket recv buffer has data that has not been loaded into the user-space, then the kernel sends an RST to the downstream because the data was TCP ACKed and the application discarded it. Otherwise, the kernel sends a FIN to the downstream.Otherwise, kernel sends FIN to downstream.
Since fd is turned off, this means that if the kernel still receives a TCP packet on this TCP connection, it will drop it and respond with an
RST.
the Envoy sends a
FIN.the Envoy socket kernel status is updated to
FIN_WAIT_1orFIN_WAIT_2.
For the Downstream side, there are two possibilities:
The socket state in the Downstream kernel has been updated to
CLOSE_WAITby theFINsent by the Envoy, but not in the Downstream program (user-space) (i.e., theCLOSE_WAITstate is not sensed).The Downstream kernel has not received the
FINdue to network delays, etc. So the Downstream program re-used theCLOSE_WAITstate.
So the Downstream program re-uses the socket and sends an HTTP Request (assuming it is split into multiple IP packets). The result is that when one of the IP packets reaches the Envoy kernel, the Envoy kernel returns an RST, and the Downstream kernel closes the socket when it receives the RST, so the socket write from one of the sockets fails. The failure message is something like Upstream connection reset. Note that socket write() is an asynchronous process, and does not wait for the ACK from the other end to return. One possibility is that one of the write() sockets has failed.
One possibility is that one of the
write()s found to have failed. This is more the behavior of the http client library for http keepalive. Or it could be the behavior of splitting multiple IP packets when the HTTP Body is much larger than the socket sent buffer. One possibility is that the ACK is not returned until `ccrypton’.One possibility is that the failure was not realized until
close(), when it had to wait for an ACK. This is more the behavior of a non-http keepalive http client library. Or it could be the behavior of the last request of the http client library that is http keepalive.
From the HTTP level, there are two scenarios where this problem can occur:
Server Prematurely/Early Closes Connection.
Downsteam writes the HTTP Header and then writes the HTTP Body, however, Envoy writes the Response and
close(fd)' the socket before reading the HTTP Body, this is calledServer Prematurely /Early Closes Connection’. /This is called `Server Prematurely Closes Connection’. Don’t think for a moment that the Envoy won’t write Response and close the socket before it’s finished reading the Request. There are at least a few possibilities:The Header is all that is needed to determine if a request is illegal. That’s why most of them return a status code of 4xx/5xx.
The HTTP Request Body exceeds the Envoy’s maximum limit of
max_request_bytes.
In this case, there are two cases:
The Downstream socket status may be
CLOSE_WAIT. The state ofwrite()is also possible. But if this HTTP Body is received by the Envoy’s Kernel, since the socket has already executedclose(fd), the socket’s file fd has already been closed, so the Kernel will directly discard the HTTP Body and returnRSTto the other side (since the socket’s file fd has already been closed, there is no more process that can read the data). (since the socket’s file fd is closed, no process can read the data). At this point, poor Downstream will say something likeConnection reset by peer.When the Envoy calls
close(fd), the kernel realizes that the kernel’s socket buffer has not been fully consumed by the user-space. In this case, kernel sendsRSTto Downstream, and eventually, poor Downstream gets an error likeConnection reset by peerwhen trying towrite(fd)orread(fd).See: Github Issue: http: not proxying 413 correctly#2929
+----------------+ +-----------------+ |Listner A (8000)|+---->|Listener B (8080)|+----> (dummy backend) +----------------+ +-----------------+
This issue is happening, because Envoy acting as a server (i.e. listener B in @lizan’s example) closes downstream connection with pending (unread) data, which results in TCP RST packet being sent downstream.
Depending on the timing, downstream (i.e. listener A in @lizan’s example) might be able to receive and proxy complete HTTP response before receiving TCP RST packet (which erases low-level TCP buffers), in which case client will receive response sent by upstream (413 Request Body Too Large in this case, but this issue is not limited to that response code), otherwise client will receive 503 Service Unavailable response generated by listener A (which actually isn’t the most appropriate response code in this case, but that’s a separate issue).
The common solution for this problem is to half-close downstream connection using ::
shutdown(fd_, SHUT_WR)and then read downstream until EOF (to confirm that the other side received complete HTTP response and closed connection) orshort timeout.
A possible way to minimize this race condition is to delay closing the socket. Envoy already has a configuration for this: [delayed_close_timeout](https://www.envoyproxy.io/docs/envoy/latest/api-v3/ extensions/filters/network/http_connection_manager/v3/http_connection_manager.proto#:~:text=is%20not%20specified.-,delayed_close_ timeout,-(Duration)/v3/http_connection_manager.proto#:~:text=is%20not%20specified. timeout,-(Duration)%20The)
Downstream does not realize that the HTTP Keepalive Envoy connection is closed and re-uses the connection.
When the Keepalive connection was reused as mentioned above, the Envoy had already called the kernel’s
close(fd)to change the socket to theFIN_WAIT_1/FIN_WAIT_2state, and had already issued aFIN. But Downstream doesn’t receive it, or receives it but the application doesn’t sense it, and at the same time reuses the http keepalive connection to send the HTTP request. at the TCP protocol level, this is ahalf-closeconnection, and the non-close side can indeed send data to the other side. However, the kernel (on the Envoy side), which has already calledclose(fd), when it receives the packet, discards it and returnsRSTto the other side (since the socket’s file, fd, is already closed, and there is no more process that can read the data). At this point, poor Downstream will say something likeConnection reset by peer.A possible way to minimize this race condition is to make the Upstream peer configure a smaller timeout than the Envoy. Let Upsteam close the connection proactively.
Mitigation on Envoy implementation#
Mitigation Server Prematurely/Early Closes Connection#
Github Issue: http: not proxying 413 correctly #2929
In the case envoy is proxying large HTTP request, even upstream returns 413, the client of proxy is getting 503.
Github PR: network: delayed conn close #4382, add new configuration item
delayed_close_timeout.Mitigate client read/close race issues on downstream HTTP connections by adding a new connection close type ‘
FlushWriteAndDelay’. This new close type flushes the write buffer on a connection but does not immediately close after emptying the buffer (unlikeConnectionCloseType::FlushWrite).A timer has been added to track delayed closes for both ‘
FlushWrite’ and ‘FlushWriteAndDelay’. Upon triggering, the socket will be closed and the connection will be cleaned up.Delayed close processing can be disabled by setting the newly added HCM ‘
delayed_close_timeout’ config option to 0.Risk Level: Medium (changes common case behavior for closing of downstream HTTP connections) Testing: Unit tests and integration tests added.
But the PR above mitigates the problem while also impacting performance:
Github Issue: HTTP/1.0 performance issues #19821
I was about to say it’s probably delay-close related.
So HTTP in general can frame the response with one of three ways: content length, chunked encoding, or frame-by-connection-close.
If you don’t haven an explicit content length, HTTP/1.1 will chunk, but HTTP/1.0 can only frame by
connection close(FIN).Meanwhile, there’s another problem which is that if a client is sending data, and the request has not been completely read, a proxy responds with an error and closes the connection, many clients will get a TCP RST (due to uploading after FIN(
close(fd))) and not actually read the response. That race is avoided withdelayed_close_timeout.It sounds like Envoy could do better detecting if a request is complete, and if so, framing with immediate close and I can pick that up. In the meantime if there’s any way to have your backend set a
content lengththat should work around the problem, or you can lower delay close in the interim.
Then it should be fixed again:
Github PR: http: reduce delay-close issues for HTTP/1.1 and below #19863
Skipping delay close for:
HTTP/1.0 framed by connection close (as it simply reduces time to end-framing)
as well as HTTP/1.1 if the request is fully read (so there’s no FIN-RST race)。即系如果
Addresses the Envoy-specific parts of #19821 Runtime guard:
envoy.reloadable_features.skip_delay_closeAlso appears in Release Note for Envoy 1.22.0. Note that delayed_close_timeout will not take effect in many cases so as not to affect performance:
http: avoiding
delay-closefor:
HTTP/1.0 responses framed by
connection: closeas well as HTTP/1.1 if the request is fully read.
This means for responses to such requests, the FIN will be sent immediately after the response. This behavior can be temporarily reverted by setting
envoy.reloadable_features.skip_delay_closeto false. If clients are seen to be receiving sporadic partial responses and flipping this flag fixes it, please notify the project immediately.
Envoy sends a request to an Upstream connection that has been closed by the Upstream#
Github Issue: Envoy (re)uses connection after receiving FIN from upstream #6815 With Envoy serving as HTTP/1.1 proxy, sometimes Envoy tries to reuse a connection even after receiving FIN from upstream. In production I saw this issue even with couple of seconds from FIN to next request, and Envoy never returned FIN ACK (just FIN from upstream to envoy, then PUSH with new HTTP request from Envoy to upstream). Then Envoy returns 503 UC even though upstream is up and operational.
Timing diagram for a classic scenario: from [https://medium.com/@phylake/why-idle-timeouts-matter-1b3f7d4469fe](https://medium.com/@phylake/why-idle-timeouts- matter-1b3f7d4469fe)
Reverse Proxy can be interpreted as Envoy.
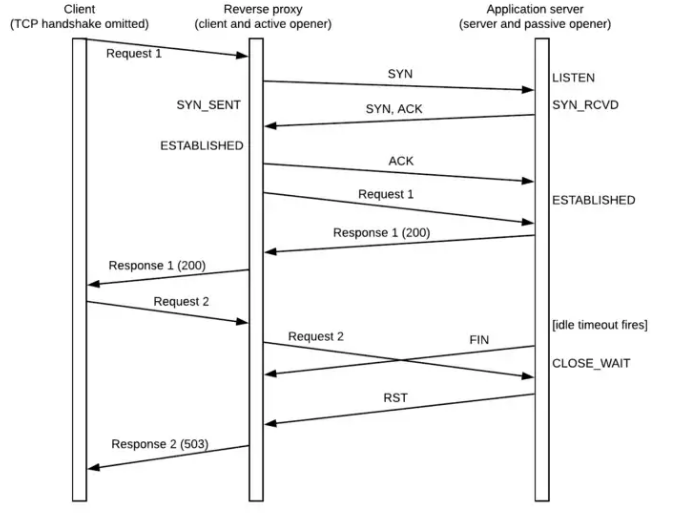
Essentially:
the Upstream peer closes the socket by calling
close(fd). this destroys the kernel’s ability to discard and respond withRSTif it still receives data on this TCP connection.the Upstream peer sends a
FIN.the Upstream socket status is updated to
FIN_WAIT_1orFIN_WAIT_2.
For the Envoy side, there are two possibilities:
The socket state in the Envoy’s kernel has already been updated to
CLOSE_WAITby theFINsent from the other end, but not in the Envoy program (user-space).The kernel where the Envoy resides has not yet received the
FINdue to network latency, etc. But the Envoy program re-used the kernel.
But the Envoy program re-uses the socket and sends (write(fd)) an HTTP Request (assuming it is split into multiple IP packets).
There are two more possibilities here:
When one of the IP packets reaches the Upstream peer, Upstream returns
RST. So any subsequent socketwritesfrom the Envoy may fail. The failure statement is something likeUpstream connection reset.Because socket
writehas a send buffer, it is an asynchronous operation. It is possible that the Envoy will only realize that the socket is closed when theEV_CLOSEDevent occurs during the next epoll event cycle after the RST is received. The failure description is something likeUpstream connection reset.
There has been some discussion in the Envoy community about this issue, but it can only be minimized, not avoided completely:
Github Issue: HTTP1 conneciton pool attach pending request to half-closed connection #2715 The HTTP1 connection pool attach pending request when a response is complete. Though the upstream server may already closed the connection, this will result the pending request attached to it end up with 503.
Protocol and Configuration can help:
HTTP/1.1 has this inherent timing issue. As I already explained, this is solved in practice by
a) setting Connection: Closed when closing a connection immediately and
b) having a reasonable idle timeout.
The feature @ramaraochavali is adding will allow setting the idle timeout to less than upstream idle timeout to help with this case. Beyond that, you should be using
router level retries.
In the end, it is impossible to avoid this problem due to a design flaw in HTTP/1.1. You have to rely on the retry mechanism for idempotent operations.
Envoy Implementation Mitigation#
In terms of implementation, the Envoy community tried to get the connection state update event by making the upstream connection go through multiple epoll event cycles and then reuse it. But this is not a good solution:
Github PR: Delay connection reuse for a poll cycle to catch closed connections.#7159(Not Merged)
So poll cycles are not an elegant way to solve this, when you delay N cycles, EOS may arrive in N+1-th cycle. The number is to be determined by the deployment so if we do this it should be configurable.
As noted in #2715, a retry (at Envoy level or application level) is preferred approach, #2715 (comment). Regardless of POST or GET, the status code 503 has a retry-able semantics defined in RFC 7231.
But in the end, it’s the connection re-use delay timer that does it:
All well behaving HTTP/1.1 servers indicate they are going to close the connection if they are going to immediately close it (Envoy does this). As I have said over and over again here and in the linked issues, this is well known timing issue with HTTP/1.1.
So to summarize, the options here are to:
Drop this change Implement it correctly with an optional re-use delay timer.
The final approach is:
Github PR: http: delaying attach pending requests #2871(Merged)
Another approach to #2715, attach pending request in next event after
onResponseComplete.The system limits an Upstream connection to one HTTP Request in an epoll event cycle, i.e. a connection cannot be re-used by more than one HTTP Request in the same epoll event cycle. This reduces the possibility that the Envoy user-space is not aware of a request that is already in the
CLOSE_WAITstate in the kernel (FIN fetched) and re-uses it.@@ -209,25 +215,48 @@ void ConnPoolImpl::onResponseComplete(ActiveClient& client) { host_->cluster().stats().upstream_cx_max_requests_.inc(); onDownstreamReset(client); } else { - processIdleClient(client); // Upstream connection might be closed right after response is complete. Setting delay=true // here to attach pending requests in next dispatcher loop to handle that case. // https://github.com/envoyproxy/envoy/issues/2715 + processIdleClient(client, true); } }Some description:envoyproxy/envoy#23625
There’s an inherent race condition that an upstream can close a connection at any point and Envoy may not yet know, assign it to be used, and find out it is closed. We attempt to avoid that by returning all connections to the pool to give the kernel a chance to inform us of
FINsbut can’t avoid the race entirely.In terms of implementation details, this Github PR itself has a bug that is fixed later: Github Issue: Missed upstream disconnect leading to 503 UC#6190
Github PR: http1: enable reads when final pipeline response received#6578
Here’s an interlude, Istio was the one that forked an envoy source in 2019 to fix the issue itself:Istio Github PR: Fix connection reuse by delaying a poll cycle. #73. In the end, though, Istio went back to the native Envoy, adding only the necessary Envoy Filter Native C++ implementation.
Istio Configuration on Mitigation#
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: passthrough-retries
namespace: myapp
spec:
workloadSelector:
labels:
app: myapp
configPatches:
- applyTo: HTTP_ROUTE
match:
context: SIDECAR_INBOUND
listener:
portNumber: 8080
filterChain:
filter:
name: "envoy.filters.network.http_connection_manager"
subFilter:
name: "envoy.filters.http.router"
patch:
operation: MERGE
value:
route:
retry_policy:
retry_back_off:
base_interval: 10ms
retry_on: reset
num_retries: 2
或
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: qqq-destination-rule
spec:
host: qqq.aaa.svc.cluster.local
trafficPolicy:
connectionPool:
http:
idleTimeout: 3s
maxRetries: 3